[This is the first of a number of postings on the topic of text mining. More specifically, this is the first draft of an introductory section of a hands-on bootcamp scheduled for ELAG 2018. As I write the bootcamp’s workbook, I hope to post things here. Your comments are most welcome. –ELM]
 Text mining is a process used to identify, enumerate, and analyze syntactic and semantic characteristics of a corpus, where a corpus is a collection of documents usually in the form of plain text files. The purpose of this process it to bring to light previously unknown facts, look for patterns & anomalies in the facts, and ultimately have a better understanding of the corpora as a whole.
Text mining is a process used to identify, enumerate, and analyze syntactic and semantic characteristics of a corpus, where a corpus is a collection of documents usually in the form of plain text files. The purpose of this process it to bring to light previously unknown facts, look for patterns & anomalies in the facts, and ultimately have a better understanding of the corpora as a whole.
The simplest of text mining processes merely count & tabulate a document’s “tokens” (usually words but sometimes syllables). The counts & tabulations are akin to the measurements and observations made in the physical and social sciences. Statistical methods can then be applied to the observations for the purposes of answering questions such as:
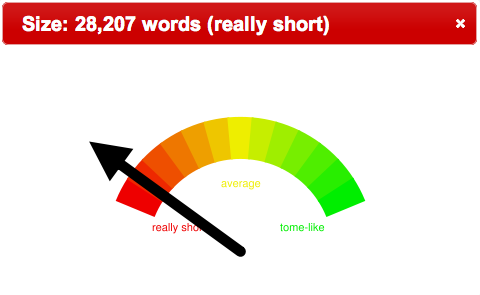
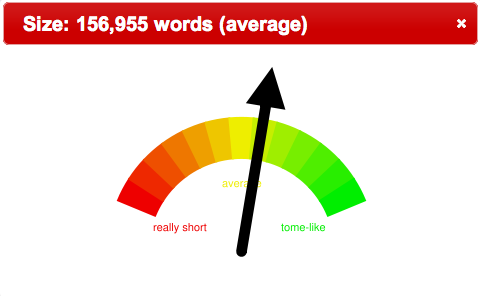
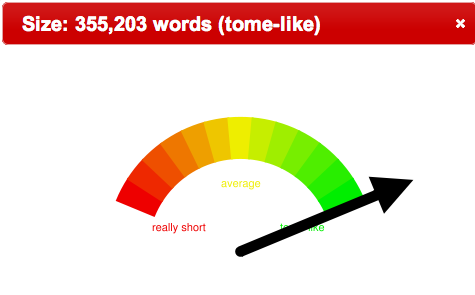
- What is the average length of documents in the collection, and do they exhibit a normal distribution?
- What are the most common words/phrases in a document?
- What are the most common words/phrases in a corpus?
- What are the unique words/phrases in a document?
- What are the infrequent words/phrases in a corpus?
- What words/phrases exist in every document and to what extent?
- Where do given words/phrases appear in a text?
- What other words surround a given word/phrase?
- What words/phrases are truly representative of a document or corpus?
- If a document or corpus where to be described in a single word, then what would that word be? How about described in three words? How about describing a document with three topics where each topic is denoted with five words?
The answers to these questions bring to light a corpus’s previously unknown features enabling the reader to use & understand a corpus more fully. Given the answers to these sorts of questions, a person can learn when Don Quixote actually tilts at windmills, to what degree does Thoreau’s Walden use the word “ice” in the same breath as “pond”, or how has the defintion of “scientific practice” has evolved over time?
Given models created from the results of natural language processing, other characteristics (sentences, parts-of-speech, named entities, etc.) can be parsed. These values can also be counted & tabulated enabling the reader to answer new sets of questions:
- How difficult is a document to read?
- What is being discussed in a corpus? To what degree are the things the names of people, organizations, places, dates, money amounts, etc? What percentage of the personal pronouns are male, female, or neutral?
- What is the action in a corpus? What things happen in a document? Are things explained? Said? Measured?
- How are things in the corpus described? Overall, are the connotations positive or negative? Do the connotations evolve within a document?
The documents in a corpus are often associated with metadata such as authors, titles, dates, subjects/keywords, numeric rankings, etc. This metadata can be combined with measurements & observations to answer questions like:
- How have the use of specific words/phrases waxed & waned over time?
- To what degree do authors write about a given concept?
- What are the significant words/phrases described with a given genre?
- Are there correlations between words/phrases and given document’s usefulness score?
Again, text mining is a process, and the process usually includes the following steps:
- Articulating a research question
- Amassing a corpus to study
- Coercing the corpus into a form amenable to computer processing
- Taking measurements and making observations
- Analyzing the results and drawing conclusions
Articulating a research question can be as informally stated as, “I’d like to know more about this corpus” or “I’d like to garner an overview of the corpus before I begin reading it in earnest.” On the other hand, articulating a research question can be as formal as a dissertation’s thesis statement. The purpose of articulating a research question — no matter how formal — is to give you a context for your investigations. Knowing a set of questions to answer helps you determine what tools you will employ in your inquires.
 Creating a corpus is not always as easy as you might think. The corpus can be as small as a single document, or as large as millions. The “documents” in the corpus can be anything from tweets from a Twitter feed, Facebook postings, survey comments, magazine or journal articles, reference manuals, books, screen plays, musical lyrics, etc. The original documents may have been born digital or not. If not, then they will need to be digitized in one way or another. It is better if each item in the corpus is associated with metadata, such as authors, titles, dates, keywords, etc. Actually obtaining the documents may be impeded by copyrights, licensing restrictions, or hardware limitations. Once the corpus is obtained, it is useful to organize it into a coherent whole. There is a lot of possible for when it comes to corpus creation.
Creating a corpus is not always as easy as you might think. The corpus can be as small as a single document, or as large as millions. The “documents” in the corpus can be anything from tweets from a Twitter feed, Facebook postings, survey comments, magazine or journal articles, reference manuals, books, screen plays, musical lyrics, etc. The original documents may have been born digital or not. If not, then they will need to be digitized in one way or another. It is better if each item in the corpus is associated with metadata, such as authors, titles, dates, keywords, etc. Actually obtaining the documents may be impeded by copyrights, licensing restrictions, or hardware limitations. Once the corpus is obtained, it is useful to organize it into a coherent whole. There is a lot of possible for when it comes to corpus creation.
Coercing a corpus into a form amenable to computer processing is a chore in an of itself. In all cases, the document’s text needs to be in “plain” text. These means the document includes only characters, numbers, punctuation marks, and a limited number of symbols. Plain text files include no graphical formatting. No bold. No italics, no “codes” denoting larger or smaller fonts, etc. Documents are usually manifested as files on a computer’s file system. The files are usually brought together as lists, and each item in the list have many attributes — the metadata describing each item. Furthermore, each document may need to be normalized, and normalization may include changing the case of all letters to lower case, parsing the document into words (usually called “features”), identifying the lemmas or stems of a word, eliminating stop/function words, etc. Coercing your corpus into coherent whole is not to be underestimated. Remember the old adage, “Garbage in, garbage out.”
Ironically, taking measurements and making observations is the easy part. There are a myriad of tools for this purpose, and the bulk of this workshop describes how to use them. One important note: it is imperative to format the measurements and observations in a way amenable to analysis. This usually means a tabular format where each column denotes a different observable characteristic. Without formating measurements and observation in tabular formats, it will be difficult to chart and graph any results.
Analyzing the results and drawing conclusions is the subprocess of looping back to Step #1. It is where you attempt to actually answer the questions previously asked. Keep in mind that human interpretation is a necessary part of this subprocess. Text mining does not present you with truth, only facts. It is up to you to interpret the facts. For example, suppose the month is January and the thermometer outside reads 32º Fahrenheit (0º Centigrade), then you might think nothing is amiss. On the other hand, suppose the month is August, and the thermometer still reads 32º, then what might you think? “It is really cold,” or maybe, “The thermometer is broken.” Either way, you bring context to the observations and interpret things accordingly. Text mining analysis works in exactly the same way.
 Finally, text mining is not a replacement for the process of traditional reading. Instead, it ought to be considered as complementary, supplemental, and a natural progression of traditional reading. With the advent of ubiquitous globally networked computers, the amount of available data and information continues to grow exponentially. Text mining provides a means to “read” massive amounts of text quickly and easily. The process is akin the inclusion of now-standard parts of a scholarly book: title page, verso complete with bibliographic and provenance metadata, table of contents, preface, introduction, divisions into section and chapters, footnotes, bibliography, and a back-of-the-book index. All of these features make a book’s content more accessible. Text mining processes applied to books is the next step in accessibility. Text mining is often described as “distant” or “scalable” reading, and it is often contrasted with the “close” reading. This is a false dichotomy, but only after text mining becomes more the norm will the dichotomy fade.
Finally, text mining is not a replacement for the process of traditional reading. Instead, it ought to be considered as complementary, supplemental, and a natural progression of traditional reading. With the advent of ubiquitous globally networked computers, the amount of available data and information continues to grow exponentially. Text mining provides a means to “read” massive amounts of text quickly and easily. The process is akin the inclusion of now-standard parts of a scholarly book: title page, verso complete with bibliographic and provenance metadata, table of contents, preface, introduction, divisions into section and chapters, footnotes, bibliography, and a back-of-the-book index. All of these features make a book’s content more accessible. Text mining processes applied to books is the next step in accessibility. Text mining is often described as “distant” or “scalable” reading, and it is often contrasted with the “close” reading. This is a false dichotomy, but only after text mining becomes more the norm will the dichotomy fade.
All that said, the totality of this hands-on workshop is based on the following outline:
- What is text mining, and why should I care?
- Creating a corpus
- Creating a plain text version of a corpus with Tika
- Using Voyant Tools to do some “distant” reading
- Using a concordance, like AntConc, to facilitate searching keywords in context
- Creating a simple word list with a text editor
- Cleaning & analyzing word lists with OpenRefine
- Charting & graphing word lists with Tableau Public
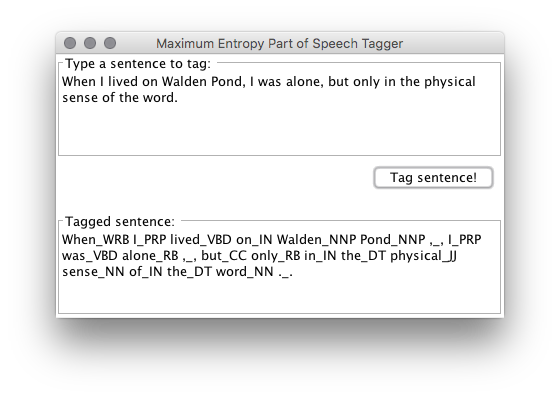
- Increasing meaning by extracting parts-of-speech with the Standford POS Tagger
- Increasing meaning by extracting named entities with the Standford NER
- Identifying themes and clustering documents using MALLET
By the end of the workshop you will have increased your ability to:
- identify patterns, anomalies, and trends in a corpus
- practice both “distant” and “scalable” reading
- enhance & complement your ability to do “close” reading
- use & understand any corpus of poetry or prose
The workshop is operating system agnostic, and all the software is freely available on the ‘Net, or already installed on your computer. Active participation requires zero programming, but readers must bring their own computer, and they must be willing to learn how to use a text editor such as NotePad++ or BBEdit. NotePad, WordPad and TextEdit are totally insufficient.


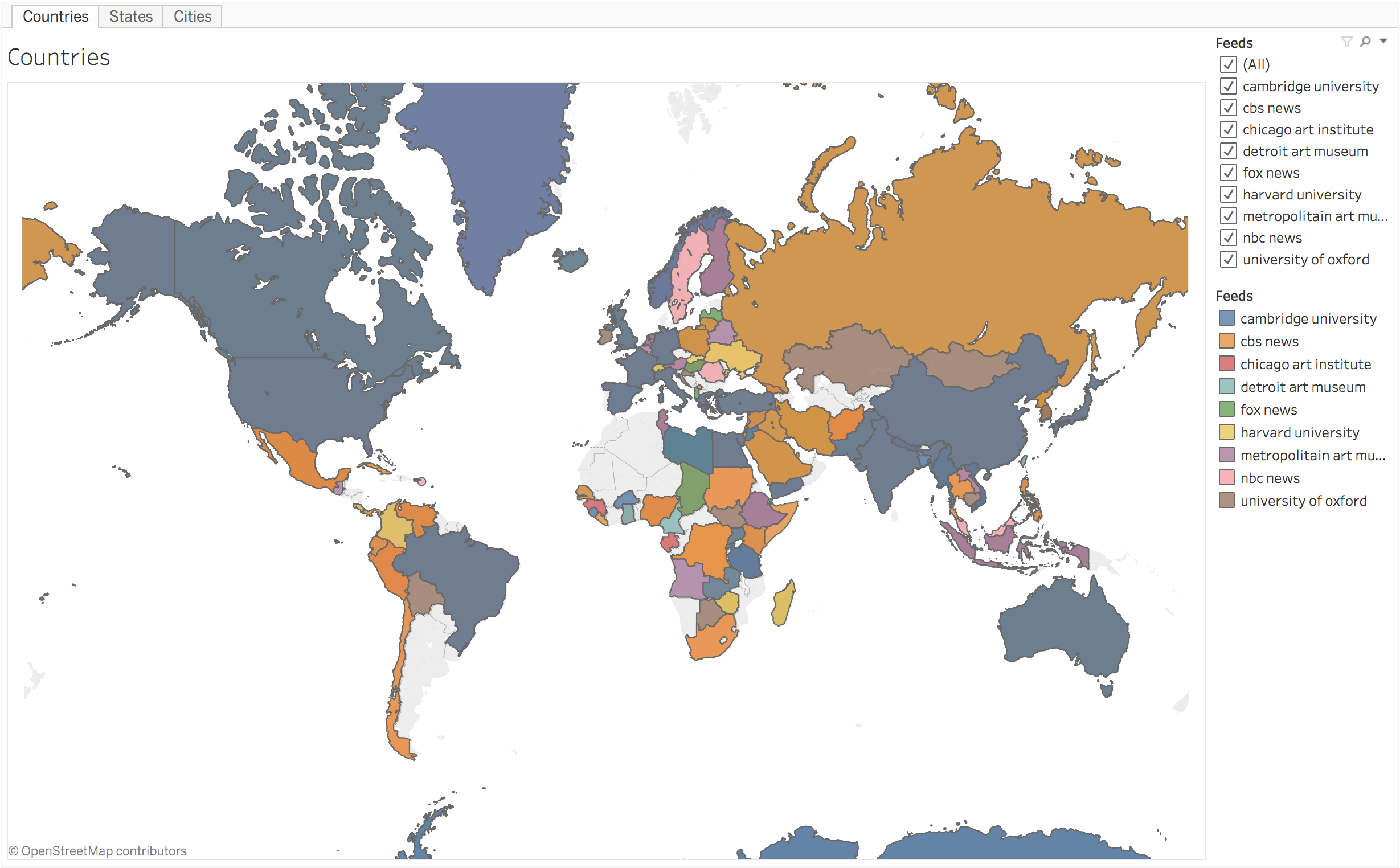
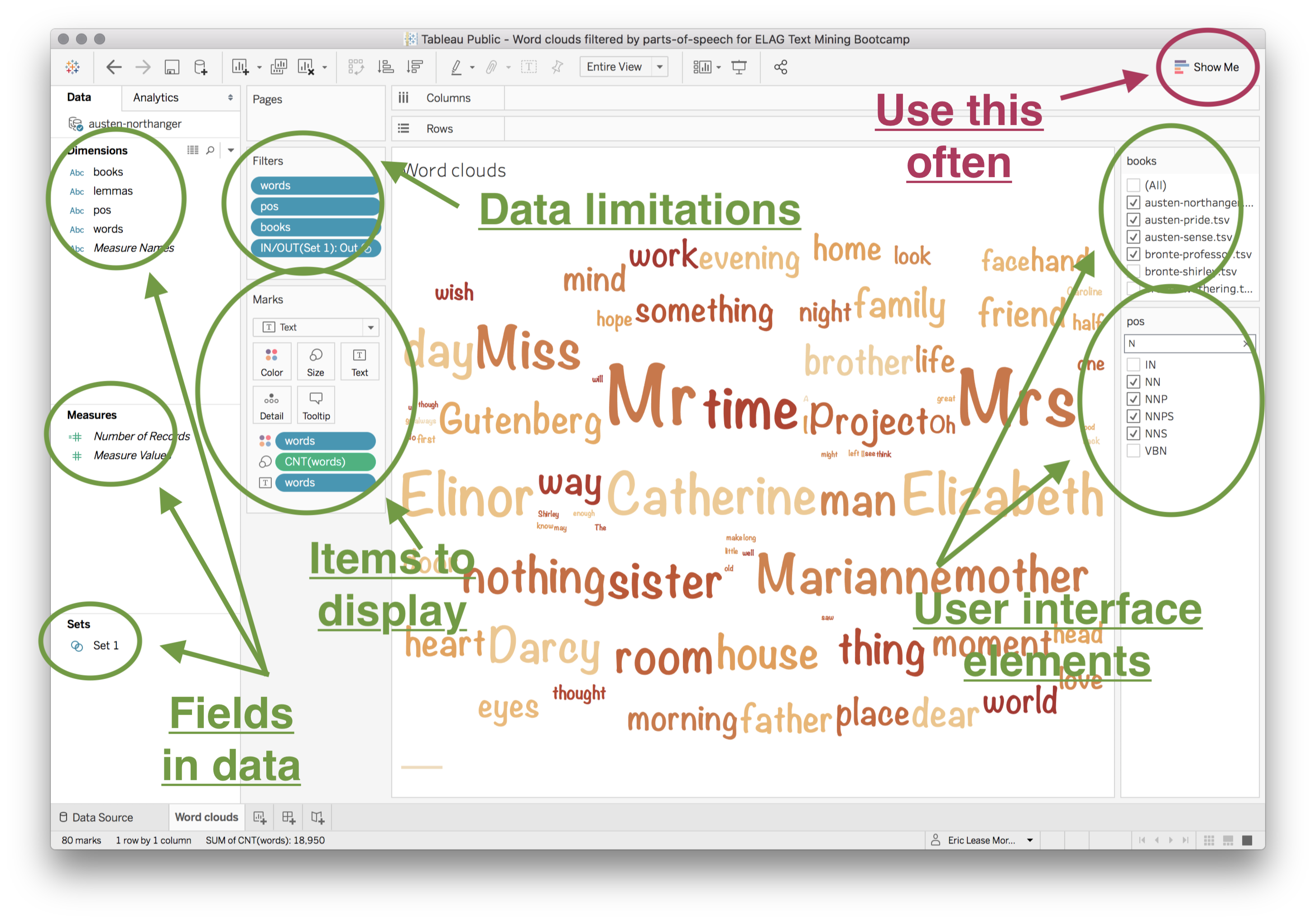
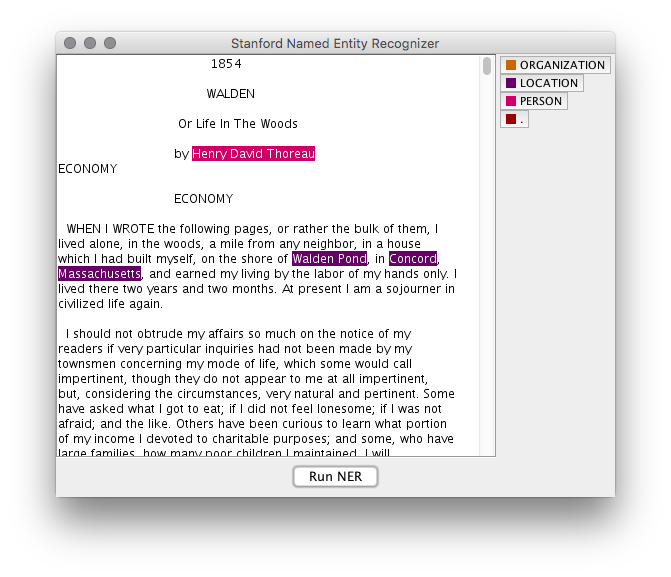


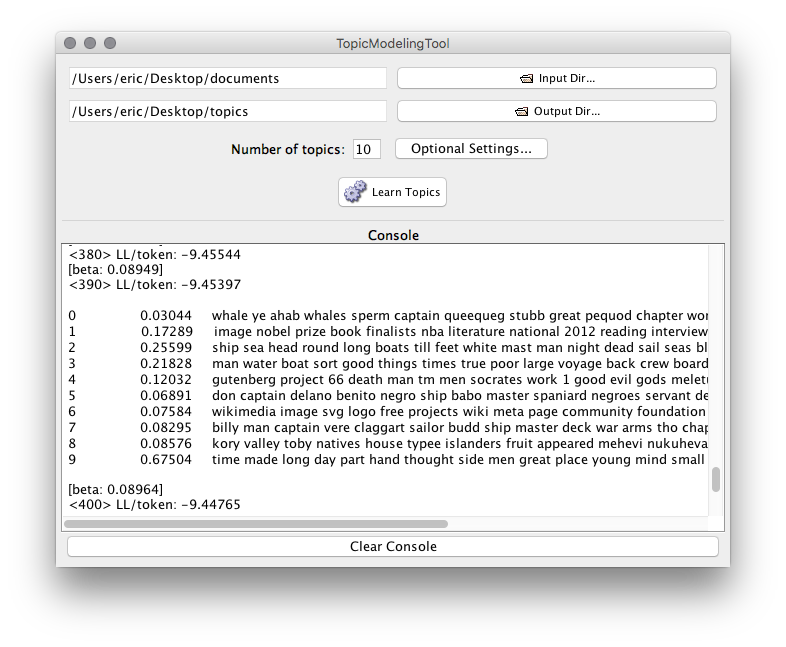
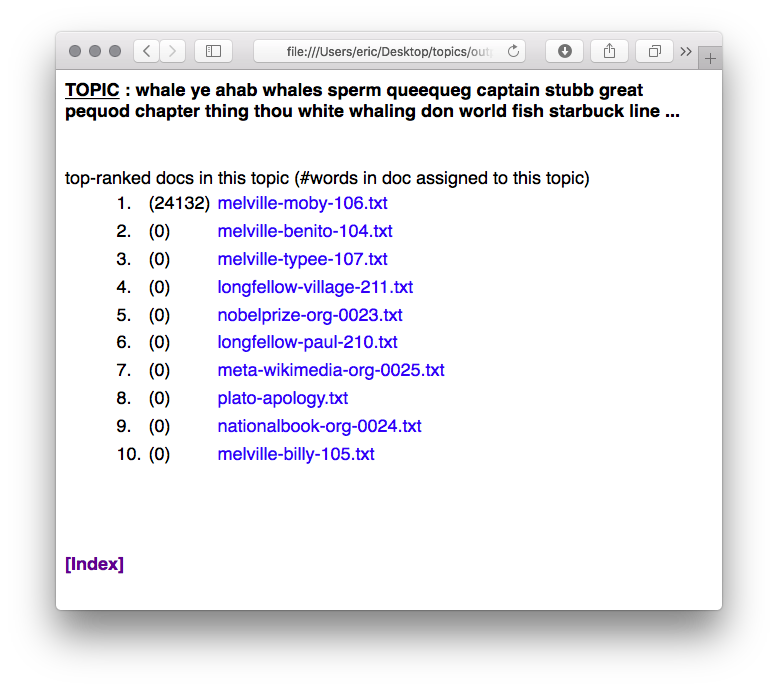

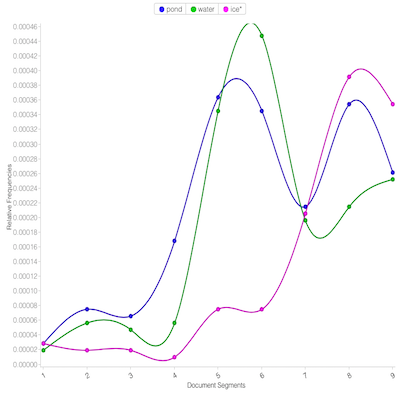
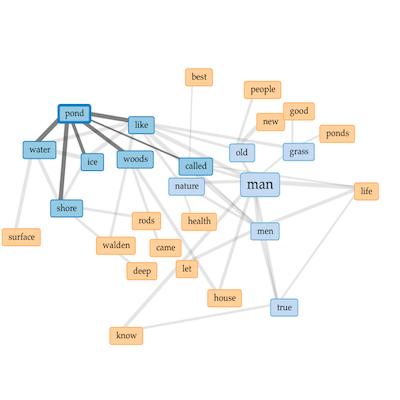
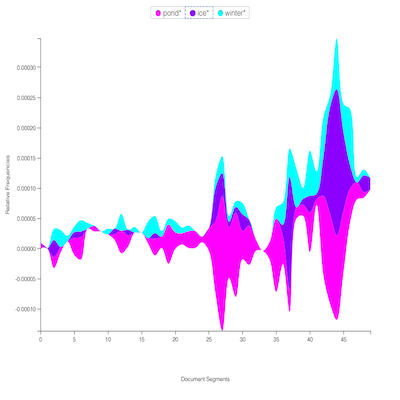
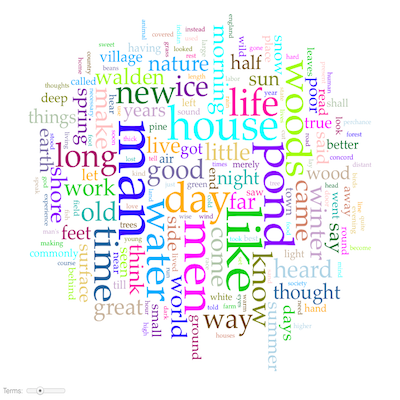


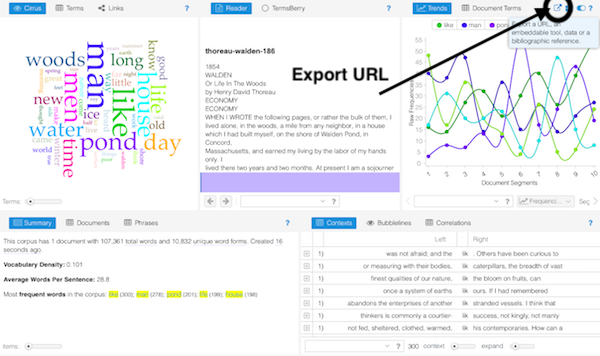
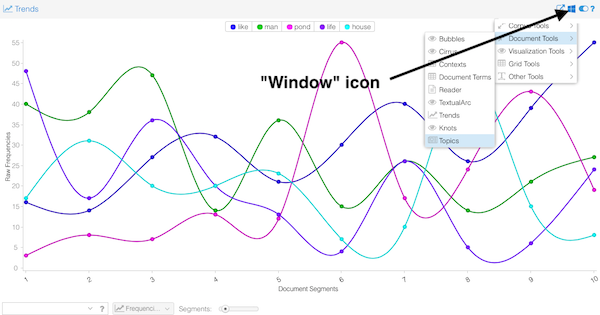
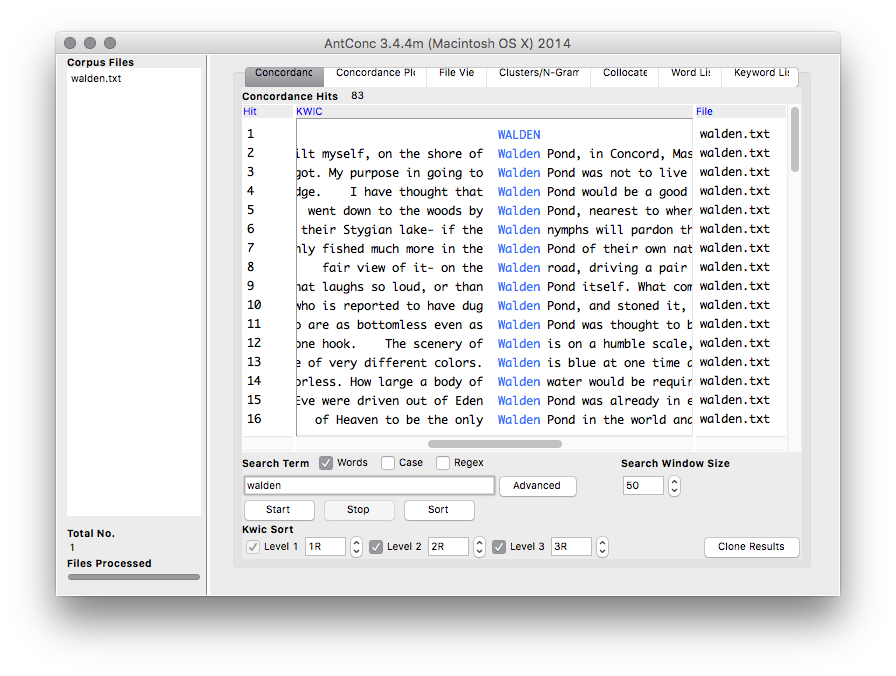 AntConc is a free, cross-platform concordance program that does all of the things listed above, as well as a few others. [1] The interface is not as polished as some other desktop applications, and sometimes the usability can be frustrating. On the other hand, given practice, the use of AntConc can be quite illuminating. After downloading and running AntConc, give these tasks a whirl:
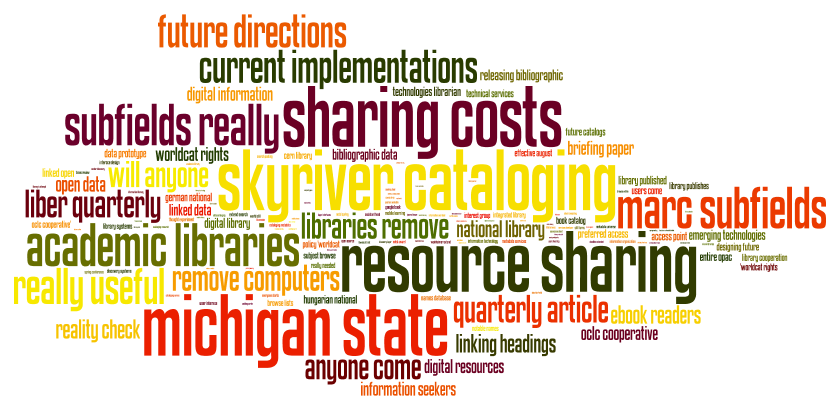
AntConc is a free, cross-platform concordance program that does all of the things listed above, as well as a few others. [1] The interface is not as polished as some other desktop applications, and sometimes the usability can be frustrating. On the other hand, given practice, the use of AntConc can be quite illuminating. After downloading and running AntConc, give these tasks a whirl: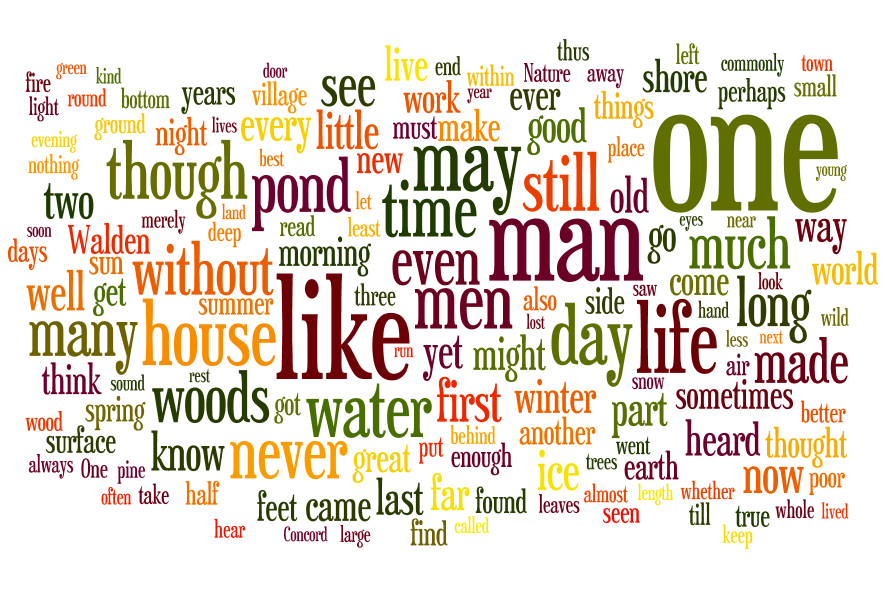 A word cloud, or sometimes called a “tag cloud” is a fun, easy, and popular way to visualize the characteristics of a text. Usually used to illustrate the frequency of words in a text, a word clouds make some features (“words”) bigger than others, sometimes colorize the features, and amass the result in a sort of “bag of words” fashion.
A word cloud, or sometimes called a “tag cloud” is a fun, easy, and popular way to visualize the characteristics of a text. Usually used to illustrate the frequency of words in a text, a word clouds make some features (“words”) bigger than others, sometimes colorize the features, and amass the result in a sort of “bag of words” fashion. By default, Wordle make effort to normalize the input. It removes stop words, lower-cases letters, removes numbers, etc. Wordle then counts & tabulates the frequencies of each word to create the visualization. But the frequency of words only tells one part of a text’s story. There are other measures of interest. For example, the reader might want to create a word cloud of ngram frequencies, the frequencies of parts-of-speech, or even the log-likelihood scores of significant words. To create the sorts of visualization as word clouds, the reader must first create a colon-delimited list of features/scores, and then submit them under Wordle’s Advanced tab. The challenging part of this process is created the list of features/scores, and the process can be done using a combination of the tools described in the balance of the workshop.
By default, Wordle make effort to normalize the input. It removes stop words, lower-cases letters, removes numbers, etc. Wordle then counts & tabulates the frequencies of each word to create the visualization. But the frequency of words only tells one part of a text’s story. There are other measures of interest. For example, the reader might want to create a word cloud of ngram frequencies, the frequencies of parts-of-speech, or even the log-likelihood scores of significant words. To create the sorts of visualization as word clouds, the reader must first create a colon-delimited list of features/scores, and then submit them under Wordle’s Advanced tab. The challenging part of this process is created the list of features/scores, and the process can be done using a combination of the tools described in the balance of the workshop.
 baxter
baxter



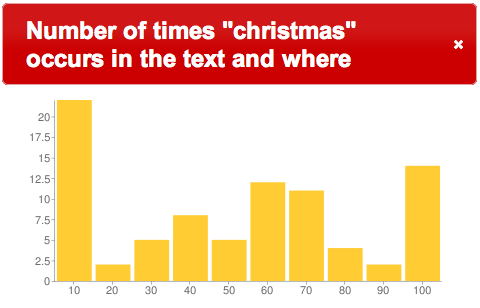



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}