
A concordance is one of the oldest of text mining tools dating back to at least the 13th century when they were used to analyze and “read” religious texts. Stated in modern-day terms, concordances are key-word-in-context (KWIC) search engines. Given a text and a query, concordances search for the query in the text, and return both the query as well as the words surrounding the query. For example, a query for the word “pond” in a book called Walden may return something like the following:
1. the shore of Walden Pond, in Concord, Massachuset 2. e in going to Walden Pond was not to live cheaply 3. thought that Walden Pond would be a good place fo 4. retires to solitary ponds to spend it. Thus also 5. the woods by Walden Pond, nearest to where I inte 6. I looked out on the pond, and a small open field 7. g up. The ice in the pond was not yet dissolved, t 8. e whole to soak in a pond-hole in order to swell t 9. oping about over the pond and cackling as if lost, 10. nd removed it to the pond-side by small cartloads, 11. up the hill from the pond in my arms. I built the
The use of a concordance enables the reader to learn the frequency of the given query as well as how it is used within a text (or corpus).
Digital concordances offer a wide range of additional features. For example, queries can be phrases or regular expressions. Search results and be sorted by the words on the left or on the right of the query. Queries can be clustered by the proximity of their surrounding words, and the results can be sorted accordingly. Queries and their nearby terms can be scored not only by their frequencies but also by the probability of their existence. Concordances can calculate the postion of a query i a text and illustrate the result in the form of a dispersion plot or histogram.
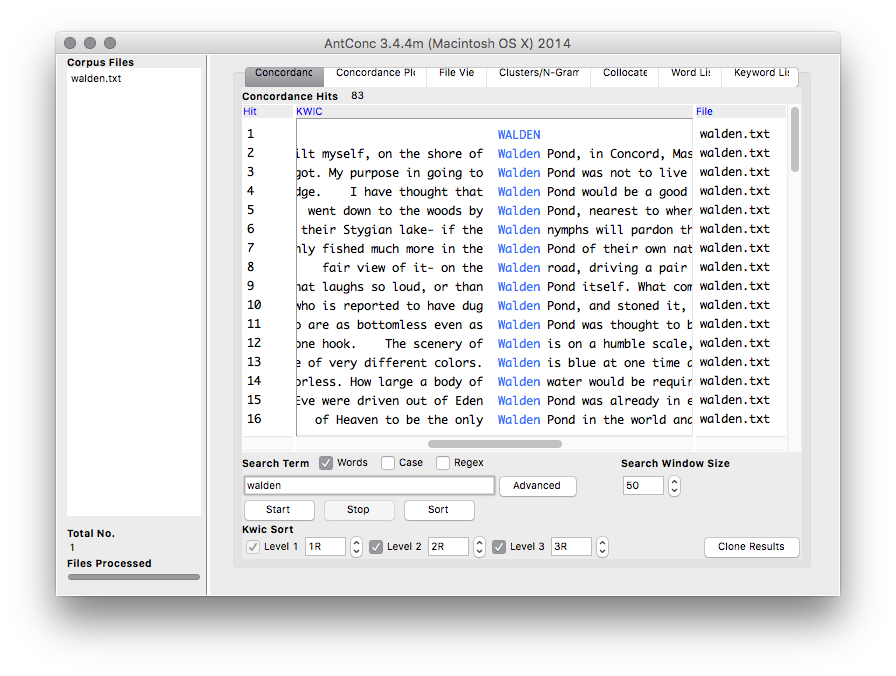 AntConc is a free, cross-platform concordance program that does all of the things listed above, as well as a few others. [1] The interface is not as polished as some other desktop applications, and sometimes the usability can be frustrating. On the other hand, given practice, the use of AntConc can be quite illuminating. After downloading and running AntConc, give these tasks a whirl:
AntConc is a free, cross-platform concordance program that does all of the things listed above, as well as a few others. [1] The interface is not as polished as some other desktop applications, and sometimes the usability can be frustrating. On the other hand, given practice, the use of AntConc can be quite illuminating. After downloading and running AntConc, give these tasks a whirl:
- use the File menu to open a single file
- use the Word List tab to list token (word) frequencies
- use the Settings/Tool Preferences/Word List Category to denote a set of stop words
- use the Word List tab to regenerate word frequencies
- select a word of interest from the frequency list to display the KWIC; sort the result
- use the Concordance Plot tab to display the dispersion plot
- select the Collocates tab to see what words are near the selected word
- sort the collocates by frequency and/or word; use the result to view the concordance
The use of a concordance is often done just after the creation of a corpus. (Remember, a corpus can include one or more text files.) But the use of a concordance is much more fruitful and illuminating if the features of a corpus are previously made explicit. Concordances know nothing about parts-of-speech nor grammer. Thus they have little information about the words they are analyzing. To a concordance, every word is merely a token — the tiniest bit of data. Whereas features are more akin to information because they have value. It is better to be aware of the information at your disposal as opposed to simple data. Do not rush to the use of a concordance before you have some information at hand.
[1] AntConc – http://www.laurenceanthony.net/software/antconc/