
Topic modeling is an unsupervised machine learning process. It is used to create clusters (read “subsets”) of documents, and each cluster is characterized by sets of one or more words. Topic modeling is good at answering questions like, “If I were to describe this collection of documents in a single word, then what might that word be? How about two?” or make statements like, “Once I identify clusters of documents of interest, allow me to read/analyze those documents in greater detail.” Topic modeling can also be used for keyword (“subject”) assignment; topics can be identified and then documents can be indexed using those terms. In order for a topic modeling process to work, a set of documents first needs to be assembled. The topic modeler then, at the very least, takes an integer as input, which denotes the number of topics desired. All other possible inputs can be assumed, such as use of a stop word list or denoting the number of time the topic modeler ought to internally run before it “thinks” it has come the best conclusion.
MALLET is the grand daddy of topic modeling tools, and it supports other functions such as text classification and parsing. [1] It is essentially a set of Java-based libraries/modules designed to be incorporated into Java programs or executed from the command line.
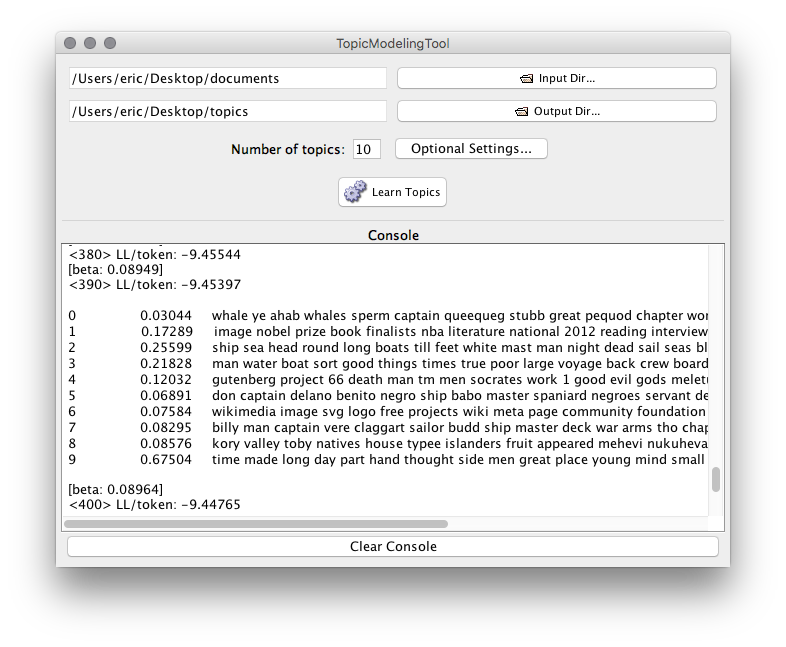
A subset of MALLET’s functionality has been implemented in a program called topic-modeling-tool, and the tool bills itself as “A GUI for MALLET’s implementation of LDA.” [2] Topic-modeling-tool provides an easy way to read what possible themes exist in a set of documents or how the documents might be classified. It does this by creating topics, displaying the results, and saving the data used to create the results for future use. Here’s one way:
- Create a set of plain text files, and save them in a single directory.
- Run/launch topic-modeling-tool.
- Specify where the set of plain text files exist.
- Specify where the output will be saved.
- Denote the number of topics desired.
- Execute the command with “Learn Topics”.
The result will be a set of HTML, CSS, and CSV files saved in the output location. The “answer” can also be read in the tool’s console.
A more specific example is in order. Here’s how to answer the question, “If I were describe this corpus in a single word, then what might that one word be?”:
- Repeat Steps #1-#4, above.
- Specify a single topic to be calculated.
- Press “Optional Settings…”.
- Specify “1” as the number of topic words to print.
- Press okay.
- Execute the command with “Learn Topics”.
 |
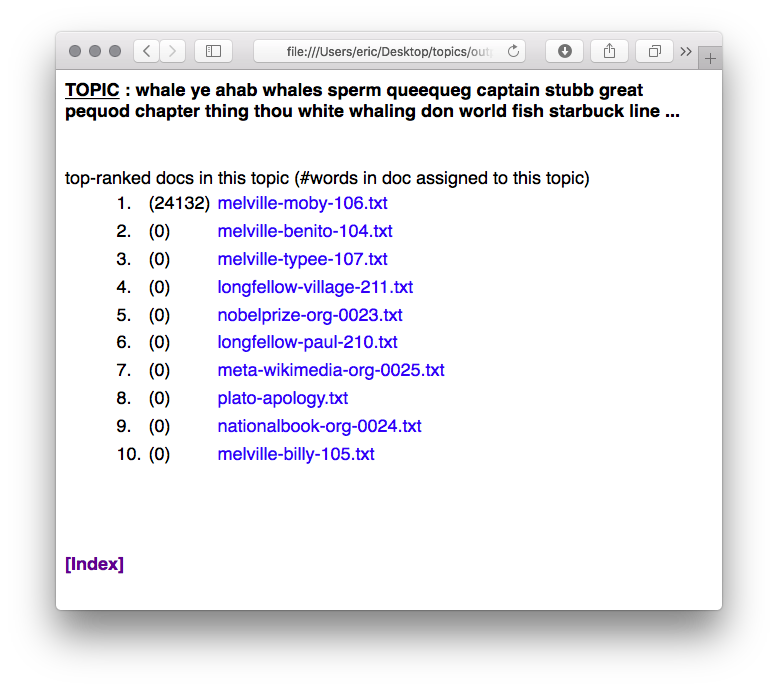 |
What one word can be used to describe your collection?
Iterate the modeling process by slowly increasing the number of desired topics and number of topic words. Personally, I find it interesting to implement a matrix of topics to words. For example, start with one topic and one word. Next, denote two topics with two words. Third, specify three topics with three words. Continue the process until the sets of words (“topics”) seem to make intuitive sense. After a while you may observe clear semantic distinctions between each topic as well as commonalities between each of the topic words. Distinctions and commonalities may include genders, places, names, themes, numbers, OCR “mistakes”, etc.
Links
- [1] MALLET – http://mallet.cs.umass.edu
- [2] topic-modeling-tool – https://github.com/senderle/topic-modeling-tool